一、DANE [2018]
《Deep Attributed Network Embedding》
网络在现实世界中无处不在,例如社交网络、学术引用网络、通信网络。在各种网络中,属性网络(
attributed network) 近年来备受关注。与仅有拓扑结构可用的普通网络(plain network)不同,属性网络的节点拥有丰富的属性信息,并有利于网络分析。例如,在学术引用网络中,不同文章之间的引用构成了一个网络,其中每个节点都是一篇文章,每个节点都有关于文章主题的、大量的文本信息。另一个例子是社交网络,用户之间可以相互联系,并且每个用户节点都有个性化的用户画像属性信息。此外,社会科学表明:节点的属性可以反映和影响其社区结构。因此,研究属性网络是必要且重要的。network embedding作为分析网络的基本工具,最近在数据挖掘和机器学习社区引起了极大的关注。network embedding在保持邻近性的同时为每个节点学习低维representation。然后,下游任务(如节点分类、链接预测、网络可视化)可以从学到的低维representation中获益。近年来,人们已经提出了各种network embedding方法,如DeepWalk, Node2Vec, LINE。然而,大多数现有的方法主要关注普通网络,忽略了节点的有用属性。例如,在Facebook或Twitter等社交网络中,每个用户都与其它用户连接,从而构成一个网络。大多数现有的方法在学习node representation时仅关注连接。但是每个节点的属性也可以提供有用的信息。一个很好的例子是用户画像。一名年轻用户可能与另一名年轻用户具有更多的相似性,而与年长用户不太相似。因此,在学习node representation时结合节点属性很重要。另外,网络的拓扑结构和节点属性是高度非线性的。因此,捕获高度非线性的特性从而发现底层模式
underlying pattern非常重要。然后,就可以在学到的node representation中更好地保留邻近性。然而,大多数现有的方法仅采用浅层模型,未能捕获到高度非线性的特性。此外,由于复杂的拓扑结构和节点属性,很难捕获这种高度非线性的特性。因此,捕获属性网络embedding的高度非线性特性是一项挑战。为解决上述问题,论文
《Deep Attributed Network Embedding》提出了一种用于属性网络的、新颖的deep attributed network embedding: DANE方法。具体而言,论文提出了一个深度模型来同时捕获网络拓扑结构和节点属性中底层的高度非线性。同时,所提出的模型可以迫使学到的node representation保持原始网络中的一阶邻近性和高阶邻近性。此外,为了从网络的拓扑结构和节点属性中学习一致(consistent) 的和互补(complementary)的representation,论文提出了一种同时结合这两种信息的新策略。另外,为了获得鲁棒的node representation,论文提出了一种有效的 “最负采样” (most negative sampling)策略来使得损失函数更鲁棒。最后,论文进行了大量的实验来验证所提出方法的有效性。相关工作:
普通网络
embedding:network embedding可以追溯到graph embedding问题,如Laplacian Eigenmaps、LPP。这些方法在保持局部流形结构(local manifold structure)的同时学习数据embedding。然而,这些方法不适用于大型网络embedding,因为它们涉及耗时的eigen-decomposition操作,其时间复杂度为最近,随着大型网络的发展,很多
network embedding纷纷出现。例如:DeepWalk采用截断的随机游走和SkipGram来学习node representation。该方法基于以下观察:随机游走中节点的分布与自然语言中的单词分布很相似。LINE提出在学习节点representation时保持一阶邻近性和二阶邻近性。GraRep在LINE的基础上进一步提出保持高阶邻近性。Node2Vec提出通过一个有偏 (biased)的随机游走来得到灵活的邻域概念。
然而,所有这些方法都仅利用了拓扑结构,而忽略了节点的有用属性。
属性网络
embedding:近年来,属性网络embedding引起了广泛的关注。人们已经为属性网络提出了各种各样的模型。TADW提出了一种inductive的矩阵分解方法来结合网络拓扑结构和节点属性。然而,它本质上是一个线性模型,对于复杂的属性网络而言是不够的。AANE和LANE采用图拉普拉斯(graph Laplacian)技术从网络拓扑结构和节点属性中学习联合embedding。《Semi-supervised classification with graph convolutional networks》提出了一种用于属性网络的图卷积神经网络模型。但是,这个模型仅是一种半监督方法,无法处理无监督的情况。《Tri-party deep network representation》提出将DeepWalk与神经网络结合起来用于network representation。尽管如此,DeepWalk部分仍然是一个浅层模型。最近,人们提出了两种无监督的深度属性网络
embedding方法:《Variational graph auto-encoders》、《Inductive representation learning on large graphs》。但是它们仅能隐式地探索拓扑结构。
因此,有必要以更有效的方式探索深度属性网络
embedding方法。
1.1 模型
1.1.1 基本概念
令
一阶邻近性定义:给定一个网络
first-order proximity)为一阶邻近性表示:如果两个节点之间存在链接则它们是相似的,否则它们是不相似的。因此,可以将一阶邻近性视为局部邻近性(
local proximity) 。高阶邻近性定义:给定一个网络
proximity matrix) 。
高阶邻近性(
high-order proximity)刻画了节点之间的邻域相似性。具体来讲:如果两个节点共享相同的邻域则它们是相似的,否则是不相似的。因此,高阶邻近性可以视为全局邻近性。语义邻近性定义:给定一个网络
semantic proximity)为:属性网络
representation learning任务的目标是学习一个映射函数
1.1.2 DANE
属性网络
embedding面临三大挑战:高度非线性:网络拓扑结构和节点属性的底层结构都是高度非线性的,这种高度非线性很难捕获。
邻近性保持:属性网络的邻近性取决于网络拓扑结构和节点属性,如何挖掘和保持邻近性关系是一个难点。
信息的一致性(
consistent)和互补性(complementary):网络拓扑结构和节点属性这两种信息源为每个节点提供了不同的视角,二者是是一致的(都能刻画节点之间的关系)、互补的(包含对方没有的信息)。因此,学到的节点embedding同时编码这两种信息的一致性、互补性非常重要。
为了解决这三个挑战,我们开发了一种新颖的
deep attributed network embedding: DANE方法。DANE利用深度神经网络分别捕获网络结构的非线性、节点属性的非线性来解决这些问题,整体架构如下。DANE有两个分支:第一个分支捕获高度非线性的网络结构,从而将输入
第二个分支捕获高度非线性的节点属性,从而将输入
这两路分支都采用深度非线性网络组成,从而捕获数据中的非线性关系。
模型的算法复杂度为
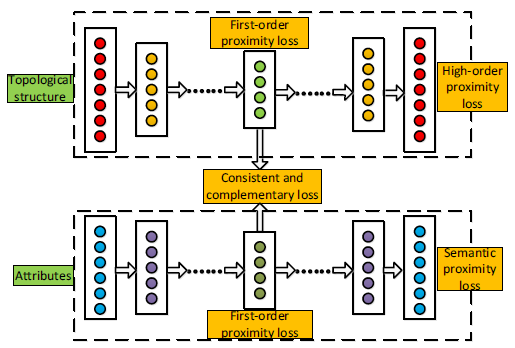
高度非线性:为捕获数据中的高度非线性,
DANE中的每一路分支都是一个自编码器。自编码器是用于feature learning的强大无监督深度模型。基本的自编码器包含三层,分别为输入层、隐层、输出层:其中:
hidden representation,自编码器的目标是最小化重构误差:
其中
为捕获网络拓扑结构和节点属性中的高度非线性,
DANE使用了其中编码器的第
embedding:在
DANE中:第一路分支的输入是高阶邻近矩阵
embedding记作第二路分支的输入是节点属性矩阵
embedding记作
邻近性保持:属性网络中存在三种类型的邻近性,语义邻近性(
semantic proximity) 、高阶邻近性(high-order proximity) 、一阶邻近性 (first-order proximity)。为保持语义邻近性,我们最小化编码器输入
原因在
《Semantic hashing》中披露。具体而言,重建损失可以强迫神经网络平滑地捕获数据流形,从而可以保持样本之间的邻近性。因此,通过最小化重建损失,我们的方法可以保持节点属性中的语义邻近性。为了保持高阶邻近性,我们最小化编码器输入
具体而言,高阶邻近性
representation也将彼此相似。一阶邻近性捕获了局部结构,因此我们也需要捕获一阶邻近性。根据一阶邻近性的定义,如果两个节点之间存在边则它们是相似的。为保持这种邻近性,我们最大化对数似然:
注意,我们需要同时保留网络拓扑结构的一阶邻近性和节点属性的一阶邻近性,以便我们可以从这两种不同来源的信息中间取得一致的结果。
对于网络拓扑结构,节点
类似地,对于节点属性,节点
因此我们定义以下目标函数从而来同时保持网络拓扑结构的一阶邻近性和节点属性的一阶邻近性:
一致性、互补性的
embedding:网络拓扑结构和节点属性是同一个网络的两种不同模态的信息,因此我们应该确保从它们中学到的embedding是一致(consistent) 的,即一致性。另一方面,这两种信息描述了同一个节点的不同方面,提供了互补的信息,因此学到的emedding应该是互补(complementary)的,即互补性。融合两种形式的
embeddingembedding。这种方式可以使得两种模式的embedding之间信息互补,但是无法确保它们之间是一致的。一致性指的是:
另一种融合的方式是:强制
DANE的两个分支采用共享的最高编码层,即embedding之间是一致的,但是丢失了大量的互补信息。因此,对于属性网络embedding,如何将网络拓扑结构和节点属性结合在一起是一个具有挑战性的问题。为了得到一致的、互补的
embedding,我们提出最大化以下似然估计:其中:
因此我们定义损失函数:
通过最小化该损失函数,我们可以强制
当它们来自于同一个节点时,尽可能地一致。但是它们又不完全相同,因此可以提供互补的信息。
当它们来自于不同节点时,尽可能推开。
但是上述损失函数的第二项过于严格。例如,如果两个节点
embedding推开。因此我们放松条件为:即:
当节点
当
为了保持节点之间的邻近性(三种类型的邻近性),并学习一致和互补的
embedding,DANE共同优化了目标函数:通过最小化该目标函数,我们获得了
representation,从而可以从网络拓扑结构和节点属性中保留一致、互补的信息。理论上可以利用超参数来平衡不同损失函数的重要性:
1.1.3 最负采样策略
考虑损失函数
实际应用中,很多链接由于各种原因未能观测到,所以邻接矩阵
embedding效果会较差。具体而言,假设当前节点为
因此参数
由于更新过程中
embedding效果越来越差。为缓解该问题,我们提出一个最负采样策略来获得更加鲁棒的
embedding。具体而言,在每次迭代过程中,我们首先计算然后对每个节点
most negative的负样本:然后基于这个最负样本,我们设置目标函数为:
采用这种最负采样策略,我们尽可能不违反潜在的相似节点,因此结果更加鲁棒。
“最负”样本本质上是最可能的“负样本”,这等价于为负样本赋予不同的置信度。
最负采样策略依赖于相似度矩阵
因此,最负采样策略并没有增加太大的额外开销。
1.2 实验
数据集:
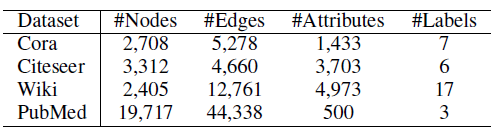
论文引用数据集:我们采用
Cora, Citeseer, PubMed三个论文引用数据集,边代表论文之间的引用链接,节点的属性为论文的Bag-Of-Word表示。Wiki数据集:维基百科数据集,边代表网页中的超链接,节点的属性为网页内容的Bag-Of-Word表示。
Baseline方法:为评估DANE的性能,我们将它与其它几种baseline方法进行比较,包括4种普通网络的embedding方法、5种属性网络embedding方法。普通网络
embedding方法:DeepWalk,Node2vec,GraRep,LINE。属性网络
embedding方法:TADW,ANE, 图自编码器Graph Auto-Encoder: GAE,变分图自编码器VGAE,SAGE。
参数配置:
对于
DeepWalk, Node2Vec,我们将窗口大小设为10、随机游走序列长度为80、每个节点开始的随机游走序列数量为10。对于
GraRep,我们设定最大转移步长为5(即从一个节点最多经过5步转移到其它节点)。对于
LINE,我们将一阶embedding和二阶embedding拼接起来作为最终embedding。所有方法的
embedding维度为200(LINE的最终embedding维度为200 + 200 = 400)。对于所有其它
baseline方法,超参数配置都参考各自的原始论文。对于
DANE,为获得高阶邻近性矩阵Deep Walk获取随机游走序列,然后使用大小为10的滑动窗口来构造高阶邻近性矩阵对于
DANE,我们使用LeakyReLU作为激活函数。DANE在四个数据集上采用不同的体系结构,如下表所示。对于每个数据集,第一行对应于网络拓扑结构的体系结构,第二行对应于节点属性的体系结构。这里我们仅给出编码器的体系结构,解码器的体系结构为编码器结构的翻转。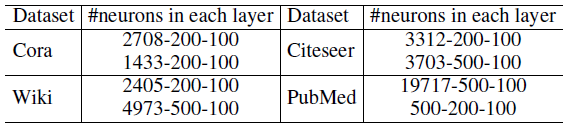
节点分类任务:我们首先使用不同的模型在数据集上通过无监督训练节点的
embedding,然后对学到的节点embedding进行节点分类任务。我们使用
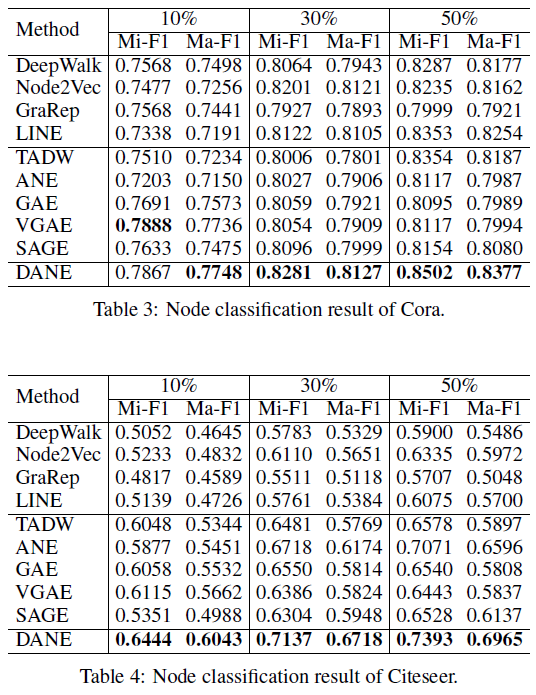
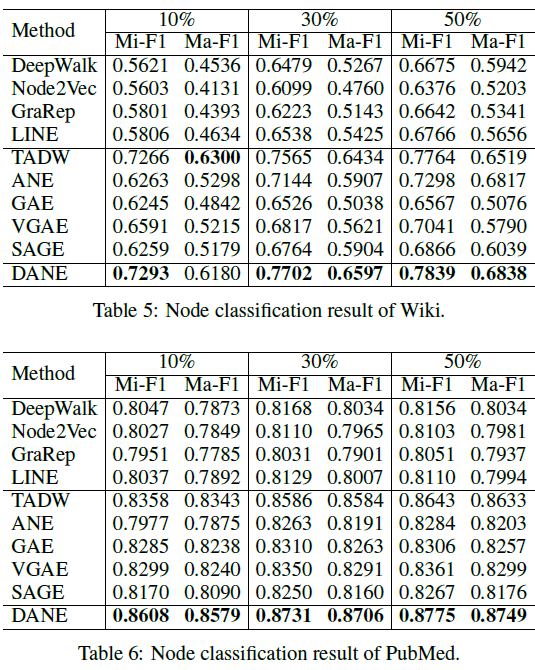
{10%,30%,50%}的节点作为训练集,剩余节点作为测试集。对于随机选择的训练集,我们使用五折交叉验证来训练分类器,然后在测试集中评估分类性能,评估指标为Micro-F1和Macro-F1。不同
embedding方法的分类性能如下表所示,结论:与普通网络
embedding方法相比,DANE取得显著提升。与属性网络
embedding方法相比,DANE大多数都效果更好。
节点聚类任务:为展示
DANE在无监督任务上的性能,我们对学到的节点embedding进行聚类。这里我们采用k-means聚类方法,并使用聚类准确率(利用标签信息来评估)作为评估指标。评估结果如下。结论:大多数情况下,DANE具有更好的聚类效果。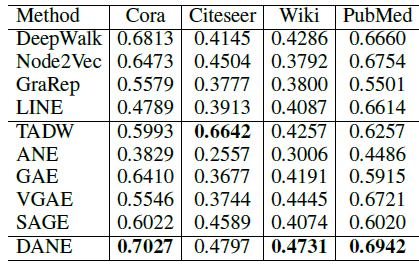
网络可视化:为进一步展示
DANE的效果,我们使用t-SNE可视化节点的embedding。我们仅给出Cora数据集的三种代表性baseline的结果。可以看到,和其它方法相比,DANE可以实现更紧凑、间隔更好的类簇。因此,我们的方法可以在有监督任务和无监督任务上实现更好的性能。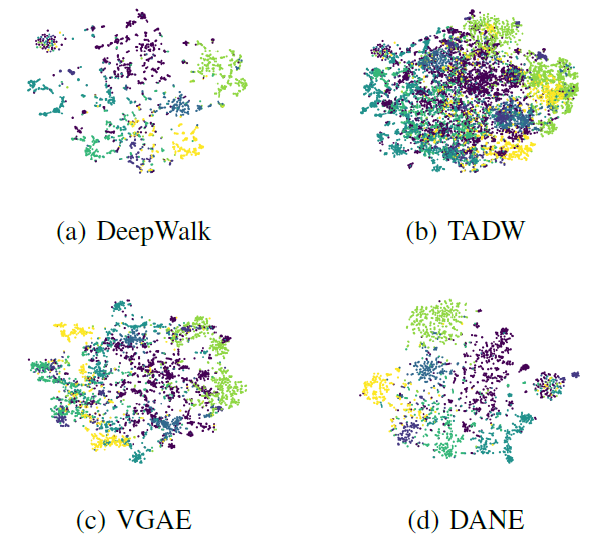
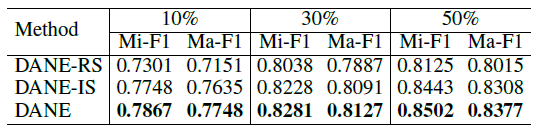
为评估采样策略的效果,我们将最负采样策略和其它两种替代方法进行比较:
第一种为随机采样策略
DANE-RS,此时负样本为随机采样得到。第二种为重要性采样策略
DANE-IS,此时负样本采样概率为:其中
直观而言,这种策略使得不相似的节点被采样为负样本的概率更大。
我们分别使用这两种采样策略来学习节点的
embedding,然后在Cora数据集上进行节点分类。结果如下所示。结论:DANE-RS性能最差,因为它无法区分不同的负样本。DANE-IS效果更好,但是比最负采样策略更差。因为最负采样策略始终可以找到最负的样本。